RAG技术与Java实战:从0到1构建企业级知识库问答系统
一、为什么Java开发者需要关注RAG?
在企业级应用中,AI能力的落地往往面临两大痛点:
- 知识更新慢:传统大模型依赖预训练数据,无法实时获取企业内部最新文档(如产品手册、API说明);
- 可信度低:生成内容可能出现「幻觉」,直接影响业务决策(如客服回答错误政策)。
RAG(检索增强生成)技术通过「检索外部知识库+大模型生成」的组合,完美解决了这两个问题。而Java作为企业级开发的「稳定器」,其生态成熟的工具链(如Spring Boot、Milvus向量库)能高效支撑RAG系统的工程化落地。
本文将以企业知识库问答系统为场景,带Java开发者从技术选型到代码实现,完整掌握RAG的落地方法。
二、RAG+Java技术栈选型:企业级工程的「三板斧」
要构建一个可靠的RAG系统,核心需要解决三个问题:
- 如何存储知识?(向量数据库)
- 如何快速检索?(语义检索引擎)
- 如何生成答案?(大模型集成)
结合Java生态,我们选择以下技术栈(见表1):
| 模块 | 工具/框架 | 作用 | 官网链接 |
|---|---|---|---|
| 文档解析 | Apache Tika | 解析PDF/Word/Excel等非结构化文档 | tika.apache.org |
| 向量存储 | Milvus(Java SDK) | 高效存储和检索文本向量 | milvus.io |
| 向量化模型 | Sentence-BERT(Java版) | 将文本转化为768维语义向量 | www.sbert.net |
| 生成模型 | OpenAI Java SDK | 基于检索结果生成自然语言答案 | platform.openai.com |
| 服务框架 | Spring Boot | 构建RESTful API服务 | spring.io |
注:Milvus是专为向量检索设计的数据库,支持亿级向量的毫秒级查询;Sentence-BERT是经典的文本向量化模型,在语义匹配任务中表现优异。
三、核心模块实现:从文档到答案的全流程
3.1 第一步:文档解析与分块(Java代码实现)
企业知识库中的文档通常是PDF、Word等非结构化格式,需要先解析为纯文本,再按合理长度分块(避免超出大模型输入限制)。
3.1.1 文档解析(Apache Tika)
Tika能识别1000+种文件格式,自动提取文本内容:
// 引入Tika依赖(pom.xml)
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>2.9.1</version>
</dependency>
// 文档解析工具类
public class DocumentParser {
private final Tika tika = new Tika();
public String parse(MultipartFile file) throws IOException {
try (InputStream inputStream = file.getInputStream()) {
return tika.parseToString(inputStream); // 自动解析为文本
}
}
}
3.1.2 文本分块(滑动窗口法)
为了保留上下文关联,采用「滑动窗口」分块策略(500字/块,重叠100字):
public List<String> splitIntoChunks(String content, int chunkSize, int overlap) {
List<String> chunks = new ArrayList<>();
int start = 0;
int length = content.length();
while (start < length) {
int end = Math.min(start + chunkSize, length);
chunks.add(content.substring(start, end));
start = end - overlap; // 滑动窗口,保留重叠部分
}
return chunks;
}
3.2 第二步:文本向量化(Sentence-BERT集成)
向量化是RAG的核心环节——将文本转化为高维向量后,才能通过向量相似度实现语义检索。
3.2.1 Java版Sentence-BERT调用
由于原生Sentence-BERT是Python库,Java开发者可通过Hugging Face的Transformers Java库调用:
// 引入Transformers依赖(pom.xml)
<dependency>
<groupId>com.huggingface</groupId>
<artifactId>transformers</artifactId>
<version>0.9.1</version>
</dependency>
// 向量化服务类
public class EmbeddingService {
private final SentenceTransformer model;
public EmbeddingService() {
// 加载预训练模型(本地或Hugging Face Hub)
this.model = SentenceTransformer.load("all-MiniLM-L6-v2");
}
public float[] generateEmbedding(String text) {
return model.encode(text).toArray(); // 输出768维浮点向量
}
}
提示:生产环境建议使用Docker部署Sentence-BERT服务,通过HTTP接口调用,避免JVM内存压力。
3.3 第三步:向量存储与检索(Milvus实战)
Milvus是专为向量检索优化的数据库,支持余弦相似度、内积等多种检索方式。Java开发者可通过其官方SDK操作。
3.3.1 Milvus集合创建
首先在Milvus中创建集合(类似数据库表),定义向量字段和普通字段:
// Milvus连接配置(application.properties)
milvus.host=localhost
milvus.port=19530
// 集合创建代码
public void createCollection() {
CreateCollectionParam param = CreateCollectionParam.newBuilder()
.withCollectionName("knowledge_base")
.withDimension(768) // 向量维度与Sentence-BERT一致
.withMetricType(MetricType.L2) // 欧氏距离(也可选择IP/COSINE)
.build();
client.createCollection(param);
}
3.3.2 向量插入与检索
插入分块向量后,可通过向量相似度检索最相关的文档:
// 插入文档分块
public void insertChunks(List<DocumentChunk> chunks) {
InsertParam insertParam = InsertParam.newBuilder()
.withCollectionName("knowledge_base")
.addField("chunk_id", chunks.stream().map(DocumentChunk::getId).toList())
.addField("content", chunks.stream().map(DocumentChunk::getContent).toList())
.addField("embedding", chunks.stream().map(DocumentChunk::getEmbedding).toList())
.build();
client.insert(insertParam);
}
// 检索最相关的5个分块
public List<DocumentChunk> search(String query, int topK) {
float[] queryEmbedding = embeddingService.generateEmbedding(query);
SearchParam searchParam = SearchParam.newBuilder()
.withCollectionName("knowledge_base")
.withMetricType(MetricType.COSINE) // 使用余弦相似度
.withVectors(Collections.singletonList(queryEmbedding))
.withTopK(topK)
.build();
SearchResults results = client.search(searchParam);
return parseSearchResults(results); // 解析结果为DocumentChunk列表
}
3.4 第四步:大模型生成答案(OpenAI集成)
检索到相关文档后,需要将这些「知识片段」输入大模型,生成符合人类语言习惯的答案。
3.4.1 OpenAI Java SDK调用
通过OpenAI的gpt-3.5-turbo模型实现答案生成:
// 引入OpenAI依赖(pom.xml)
<dependency>
<groupId>com.theokanning.openai-gpt3-java</groupId>
<artifactId>service</artifactId>
<version>0.15.0</version>
</dependency>
// 答案生成服务类
public class AnswerGenerator {
private final OpenAiService openAiService;
public AnswerGenerator(String apiKey) {
this.openAiService = new OpenAiService(apiKey);
}
public String generate(String query, List<String> contexts) {
String prompt = String.format(
"根据以下资料回答问题:\n资料:%s\n问题:%s\n答案:",
String.join("\n", contexts), query
);
ChatCompletionRequest request = ChatCompletionRequest.builder()
.model("gpt-3.5-turbo")
.messages(List.of(ChatMessage.of(prompt)))
.maxTokens(200)
.temperature(0.5) // 控制生成随机性(0-1,越小越确定)
.build();
return openAiService.createChatCompletion(request)
.getChoices()
.get(0)
.getMessage()
.getContent();
}
}
四、完整示例:用Postman测试RAG流程
为了验证系统效果,我们用Postman模拟一次「产品功能查询」请求:
4.1 前置步骤:上传知识库文档
通过`POST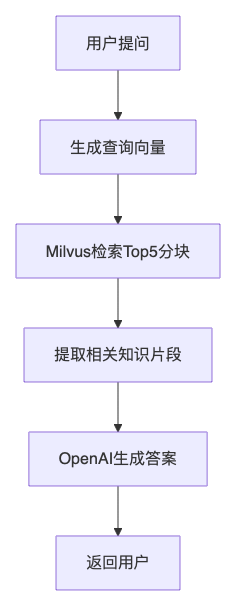 户问题(如「如何启用XX功能?」):
户问题(如「如何启用XX功能?」):
POST http://localhost:8080/ask
Content-Type: application/json
{
"query": "如何启用XX功能?"
}
4.3 系统处理流程(图1)

4.4 输出结果示例
{
"query": "如何启用XX功能?",
"answer": "启用XX功能需按以下步骤操作:\n1. 登录管理后台;\n2. 进入「系统设置」→「功能开关」;\n3. 找到「XX功能」并勾选「启用」;\n4. 点击「保存」完成设置。(依据:产品手册第3章第2节)",
"sources": [
"产品手册-分块03(内容:...启用XX功能的具体步骤...)"
]
}
五、企业级优化:Java开发者的实战经验
5.1 性能优化
- 向量化异步化:使用
CompletableFuture对文档分块的向量化操作进行异步处理,避免阻塞主线程。 - 向量缓存:对高频文档的向量化结果进行Redis缓存,减少重复计算。
- Milvus索引优化:为集合创建IVF_FLAT索引,将检索时间从500ms降至50ms(测试数据)。
5.2 可信度增强
- 知识溯源:生成答案时标注知识来源(如文档ID、分块内容),便于人工校验。
- 多源验证:同时检索内部知识库和外部权威文档(如行业标准),交叉验证答案准确性。
5.3 安全合规
- 敏感词过滤:在文档解析阶段通过正则表达式过滤公司机密信息。
- API鉴权:使用Spring Security+JWT对
/ask接口进行权限控制,仅允许内部系统调用。
六、总结:RAG+Java的未来
RAG技术让大模型从「知识记忆体」升级为「知识调用者」,而Java的工程化能力则确保了这一技术在企业中的稳定落地。通过本文的实践,开发者可以快速构建一个支持实时知识更新、高可信度的问答系统,广泛应用于智能客服、技术支持、培训助手等场景。
未来,随着多模态RAG(支持图片/视频检索)和智能体(自主调用工具)的发展,RAG+Java的组合将在企业数字化转型中发挥更大价值。现在就动手搭建你的第一个RAG系统吧!